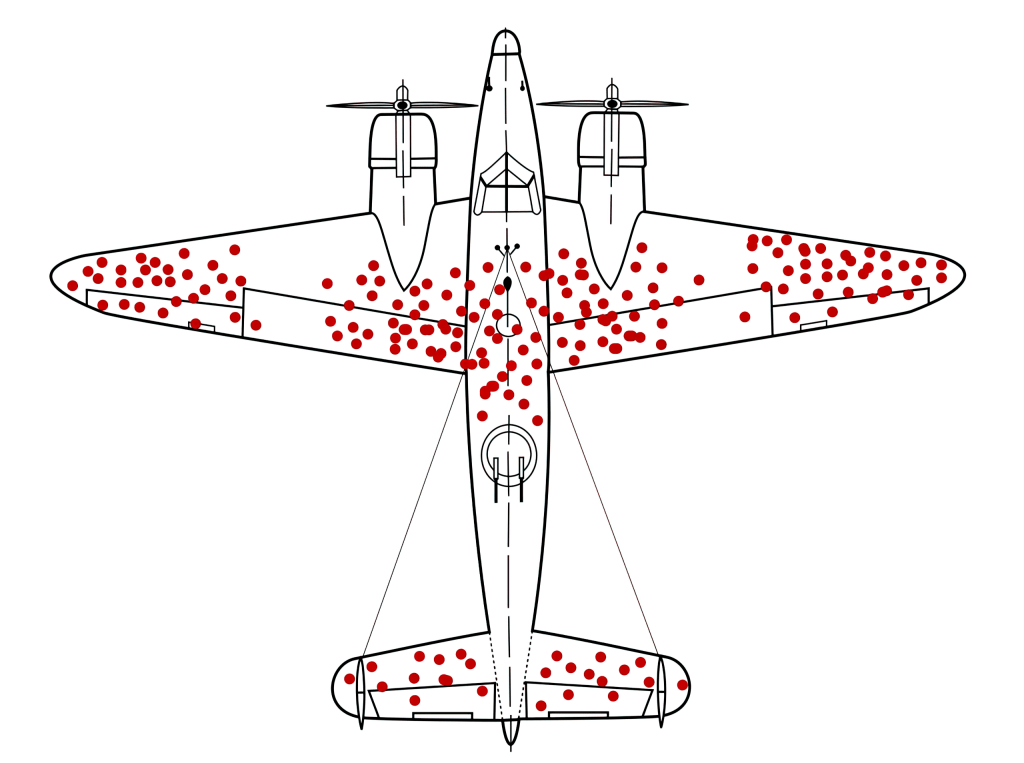
Pattern First
Abraham Wald, during World War II, examined bullet-hole patterns on returning bombers. Every other analyst in the room recommended reinforcing the areas with the most damage. Wald recommended reinforcing the areas with no holes — because planes hit there didn’t return. The story compresses a sophisticated statistical insight (selection effects in observational data) into something portable enough to cross from operations research to medicine to software engineering to business strategy.
Meanwhile, the formal treatment of selection bias — Heckman correction, propensity score matching, instrumental variables — remains locked inside statistics and econometrics despite equal or greater validity. The parable travels. The formalism stays home.
This pattern repeats across the full inventory of epistemic warnings. Feynman’s cargo cults, Goodhart’s Law, Chesterton’s fence, Russell’s chicken — each compresses a mechanism-level insight into a narrative that propagates across disciplines. Formal frameworks explaining the same mechanisms (Bayesian model criticism, complexity theory, institutional analysis) achieve far less cultural penetration despite broader applicability.
The question is what structure emerges when these parables are organized by their underlying failure mechanism rather than their discipline of origin — and whether that structure reveals anything about why some epistemic warnings persist and others keep getting reinvented.
The Families
Family 1a: Perceptual Filter
Error: The instrument limits detection, and absent evidence is silently converted into evidence of absence.
Flagship: Eddington’s Fish Net. A marine biologist surveys the ocean with a net of six-inch mesh, examines the catch, and concludes no sea creature is smaller than six inches. The tool defines the ontology.
Members: The Streetlight Effect (searching where the light is, not where the keys fell). Kaplan’s Law of the Instrument (“give a boy a hammer and everything needs pounding”).
Distinguishing feature: Remediable. The error lives in the tool, not the observer. A different net yields different data.
Family 1b: Cognitive Boundary
Error: The observer’s entire framework is the instrument, and no tool-swap can fix it because the observer cannot recognize the framework’s limits from inside it.
Flagship: The Fish and the Turtle (Ayya Khema, via Theravada tradition). A fish asks a turtle to describe land. The fish’s questions — “Is it rippling? Buoyant? Wet?” — decompose land-beauty into water-properties, destroying the information. The fish is not using the wrong tool. The fish’s ontology is the tool.
Members: Kuhn’s incommensurability between scientific paradigms. The difficulty of explaining color to someone blind from birth. Any situation where the observer’s vocabulary has no slot for the phenomenon being described.
Distinguishing feature: Not remediable by evidence or argument. Requires paradigm shift, contemplative practice, or a sufficiently disorienting experience that cracks the framework.
Diagnostic question: When repeated evidence presentation produces no convergence, you are likely in 1b, not 1a. The 1a/1b boundary is the boundary between problems that yield to more data and problems that require a different kind of observer.
Why the 1a/1b split matters: Many persistent disagreements look like filter problems (just show them the data!) when they are actually boundary problems (the data cannot be parsed inside the other party’s framework). Misdiagnosing a 1b problem as 1a leads to escalating frustration on both sides — more evidence, same impasse.
Family 2: Inventory Is Not Explanation
Error: A complete catalog of components is confused with a working theory of the system.
Flagship: Lazebnik’s Radio (Yuri Lazebnik, “Can a biologist fix a radio?”, Cancer Cell, 2002). A biologist tasked with fixing a broken radio removes components one by one and catalogs the results. Remove this transistor: horrible screeching. Conclusion: “the screeching transistor.” The complete parts list explains nothing about how the radio plays music.
Members: Borges’s 1:1 map (perfectly accurate, perfectly useless). The blind men and the elephant (six complete local descriptions that fail to compose into understanding). Pauli’s “not even wrong” — the terminal case, where a description is so vague it has no constraint structure at all and therefore cannot fail. A catalog that doesn’t even have the architecture to be falsified.
Distinguishing feature: The error is not insufficient data but the wrong kind of representation. More components in the catalog will never produce a circuit diagram.
Family 3a: Metric Capture
Error: A proxy measure becomes the goal, and optimizing the proxy degrades the thing it was supposed to measure.
Flagship: Goodhart’s Law — “When a measure becomes a target, it ceases to be a good measure.”
Members: The McNamara Fallacy (body counts in Vietnam as a proxy for strategic progress — measuring what was easy and ignoring what mattered). The Soviet nail factory (given tonnage quotas, produces one giant nail; given unit quotas, produces millions of useless tacks). Standardized testing optimized at the expense of learning.
Distinguishing feature: The system doesn’t fight back adaptively — the metric drifts from its referent through optimization pressure. The actors often don’t realize the substantive purpose has been hollowed out.
Diagnostic question: If the metric were removed, would the behavior stop? If yes — if the behavior is driven by the measure rather than by strategic intent — the error is likely 3a.
Boundary case: Goodhart’s Law spans both the empirical and social substrates (discussed below). Metric drift is an empirical phenomenon — optimization pressure changes the data-generating process. But metric gaming is strategic behavior — intelligent agents deliberately exploiting measurement systems. Many real-world Goodhart cases involve both simultaneously, which makes the family assignment context-dependent rather than absolute.
Family 3b: Adaptive Response
Error: Intervention in a reflexive or adaptive system triggers reorganization that produces the opposite of the intended outcome.
Flagship: The Cobra Effect. British colonial administrators in Delhi offered a bounty for dead cobras to reduce the population. People started breeding cobras. When the program was canceled, breeders released their stock. The cobra population increased.
Members: Campbell’s Law (the policy version of Goodhart). Seeing Like a State — James Scott’s book-length demonstration that administrative simplification destroys the informal structures that made systems function. Any case where the system reorganizes around the intervention rather than being shaped by it.
Distinguishing feature: Differs from 3a in that the system actively responds. The cobra breeders are strategic actors, not metrics drifting.
Diagnostic question: If the metric were removed, would the behavior stop? If no — if the behavior is strategic and independent of the particular measure — the error is 3b.
The split between 3a and 3b tracks the split between optimization pressure (impersonal) and adversarial reorganization (strategic). The intervention that works for 3a is redesigning the metric. The intervention that works for 3b is changing the incentive structure or removing the adversarial loop.
Family 4: Pattern Is Not Signal
Error: Discovered patterns are treated as if they were predicted. Structure is hallucinated in noise, or the target is painted around the bullet hole.
Flagship: The ISIS-2 Astrological Signs. The ISIS-2 trial on aspirin after heart attacks (The Lancet, 1988) ran a deliberately absurd subgroup analysis showing aspirin was beneficial for every astrological sign except Gemini and Libra. Published to demonstrate that slicing data enough ways always produces “significant” patterns in noise.
Members: Russell’s Chicken (inductively concludes the farmer is benevolent, right up until Christmas). The Texas Sharpshooter Fallacy (paint the target around the bullet hole). Post hoc analysis presented as hypothesis-driven research.
Distinguishing feature: The error is temporal. Treating after-the-fact discovery as though it carried the evidential weight of before-the-fact prediction. The pattern is real in the data. The signal is not.
Family 5: Form Mimics Function
Error: The institutional or procedural shape of a functional process is reproduced without the substance that made it work. The ritual is mistaken for the mechanism.
Flagship: Feynman’s Cargo Cults (1974 Caltech commencement address). South Pacific islanders who had seen military airstrips built fake runways, control towers, and coconut-shell headphones, waiting for planes to land. The form was reproduced perfectly. The mechanism was absent entirely.
Members: The replication crisis — entire fields with the institutional shape of science (peer review, methods sections, significance tests) but without the substance that those forms were supposed to ensure. Compliance theater masquerading as safety. Innovation theater in corporate settings. AI benchmarks that don’t measure what they claim.
Distinguishing feature: The mimicry is often sincere, not cynical. The cargo cult builders genuinely expected the planes. The error is sociological — mistaking process for outcome — rather than purely epistemic.
Dynamic boundary with Family 8: In practice, many systems drift across the 5/8 boundary over time. A ritual starts sincere (Family 5), actors gradually realize it can be exploited, and the system becomes strategic (Family 8). Compliance processes, academic publishing, corporate KPIs — all exhibit this phase transition. The 5/8 boundary may be better understood as states of the same system under different incentive pressures rather than as a discrete category boundary.
Family 6: Selection Distorts the Sample
Error: Reasoning from a filtered sample as though it were the population. The filtering may be invisible to the observer.
Flagship: Wald’s Bullet Holes. The analysts examining returning bombers recommended armoring the damaged areas. Wald identified the error: the sample was conditioned on survival. The planes with holes in the blank spaces never came back.
Members: Berkson’s paradox (the “why are all the attractive people I date unintelligent” structure — conditioning on a collider variable creates spurious negative correlation). Gell-Mann Amnesia (coined by Crichton: reading a newspaper article about a field one knows deeply, noticing it is riddled with errors, then turning the page and reading the next article as authoritative). The anthropic principle in cosmology. Publication bias, social media virality bias.
Distinguishing feature: The structure in the data is real, not hallucinated (distinguishing Family 6 from Family 4). However, the structure was generated by the selection process, not by the phenomenon under study. Family 4 hallucinates structure in noise. Family 6 encounters real structure that was misleadingly generated by filtering. The corrections are correspondingly different: Family 4 requires temporal discipline (pre-registration, out-of-sample testing). Family 6 requires sampling awareness (conditioning analysis, causal graph awareness).
Family 7: Dismantling Without a Causal Model
Error: Removing a structure without understanding why it exists. The structure is load-bearing in ways invisible to the reformer, and its removal collapses functions the reformer did not know depended on it.
Flagship: Chesterton’s Fence. Before removing a fence, first understand why someone built it. If the reason cannot be articulated, the fence should not be removed.
Members: The Lindy Effect (things that have survived a long time are likely to survive longer — survival as evidence of hidden function). Much of Taleb’s corpus operates at the intersection of Family 3b (adaptive response) and Family 7 (hidden function).
Distinguishing feature: The other families describe error-generating mechanisms. Family 7 describes the error of intervening without a causal model of the target system — removing structure without understanding its function. The error is not in perception, measurement, or classification, but in acting on an incomplete model as though it were complete.
The Social Families
The empirical families share an implicit assumption: the participants are trying to understand reality and failing. Testing the taxonomy against parables from oral traditions, fiction, and philosophy of argument reveals a second substrate — failures that operate on social terrain rather than empirical terrain.
The structural difference is not merely topical. The empirical families assume a shared objective function: all participants are attempting to model reality accurately and failing at different stages of the process. The social families describe situations where objective functions are not shared — at least one participant is optimizing for something other than accurate modeling, and the error belongs to whoever fails to recognize this.
This distinction predicts different intervention responses. Empirical errors should yield to better measurement, reasoning, and methodology. Social errors resist methodological reform because the “error” serves the actor’s purposes. If better epistemic methods (data, logic, rigor) systematically fail to fix a problem without accompanying incentive or positional changes, the problem is likely on the social substrate.
Diagnostic question: Does correcting the error reduce the actor’s status or power? If yes, the error is likely load-bearing on the social substrate. Methodological reform alone will not dislodge it.
Family 8: Arbitrage of Intent
Error: The gap between a rule’s formal specification and its substantive purpose is deliberately exploited by an agent who understands both.
Flagship: The Vegetarian Cat (oral tradition, popularized in various literary forms including Murakami’s 1Q84). A cat corners a rat. The rat begs for mercy. The cat says, “Don’t worry — I’m a vegetarian.” The rat relaxes. The cat pounces. The dying rat asks, “But you said you’re a vegetarian?” The cat replies, “True. I’m going to take you home and trade you for lettuce.”
Members: Malicious compliance (following orders to the letter in ways designed to cause harm). Regulatory arbitrage (exploiting the gap between economic substance and legal/regulatory treatment). The Bushman Money Magic story (Jackal’s cascading fraud, where the evidence of each scam generates the attack surface for the next — the victim’s attempt to recover creates the new exploit).
Distinguishing feature: Differs from Family 3a (Goodhart) in agency and awareness. Metric capture is systemic drift — actors often don’t realize the spirit has been killed. Intent arbitrage is adversarial exploitation — the cat knows exactly what “vegetarian” is supposed to mean and navigates the gap deliberately. Differs from Family 5 (cargo cults) because the mimicry is strategic, not sincere — though as noted above, many systems transition from sincere mimicry to strategic exploitation over time.
Family 9: Game Misidentification
Error: Treating an interaction as epistemic (about evidence and truth) when it is actually positional (about dominance, loyalty, or status). One participant assumes shared commitment to resolving a factual question. The other is playing a different game entirely.
Flagship: The Donkey and the Tiger (traditional fable, variants across Sufi, South Asian, and African oral traditions). A donkey and a tiger argue about the color of grass. The donkey says blue; the tiger says green. They go to the lion king for judgment. The lion rules the grass is blue and sentences the tiger to a year of silence — not for being wrong, but for wasting wisdom arguing with a fool. The tiger’s error was engaging an epistemic contest when the donkey was running a dominance game.
Members: The Banks/Hume mechanism (Iain M. Banks, Use of Weapons; David Hume, A Treatise of Human Nature) — reason serves the passions, so argument is almost never about the ostensible subject. “Winning” an argument attacks the justification while leaving the preference intact. The Desert Fathers parable (remediation — the disciple trained to treat insults as a commodity with a price, thereby inoculating against frame confusion). Graham’s Disagreement Hierarchy (diagnostic tool — classifying the DH level of an opponent reveals whether an epistemic contest is actually occurring).
Distinguishing feature: Every other family assumes all participants are trying to understand reality and failing. This family covers the case where at least one participant is not trying to understand reality at all, and the error belongs to whoever assumes otherwise.
The Boundary Condition
One parable resists placement in any family. Amos Burton’s description of “the churn” in The Expanse — “when the rules of the game change… the jungle tears itself down and builds itself into somethin’ new” — is not an epistemic error. It describes the substrate on which all the families operate: the fact that games end, rules restructure, and survival is orthogonal to understanding.
The Churn is the boundary condition of the taxonomy. Correct reasoning across all families does not guarantee survival when the environment restructures faster than any model can track. The taxonomy is a diagnostic manual for reasoning failures within a game. The Churn is the reminder that games end.
The Constitutive Persistence Problem
This is the taxonomy’s deepest structural finding, and it applies across almost every family: many epistemic errors persist not from ignorance but because the error-generating capability is structurally coupled to the field’s successes.
Lazebnik’s critique of parts-list biology has been in circulation since 2002. The approach persists because the entire incentive structure — grants, publications, tenure, tooling — is built on it. Reductionism produces both the field’s breakthroughs and Lazebnik’s failure mode. Metrics enable both coordination and Goodhart collapse. Institutional rituals enable both scale and cargo cult drift.
If true, this reframes intervention entirely. You cannot simply “remove the error” without also removing the capability that produces the system’s successes. Effective intervention requires rebalancing the system — changing the conditions under which the error-generating capability operates — rather than eliminating the capability itself.
What would move this from hypothesis to reasonable inference: Systematic case studies of intervention attempts against well-documented epistemic errors, comparing outcomes when the intervention addresses only the empirical error (better methods) versus when it addresses the coupling (incentive reform, structural redesign). The constitutive-persistence claim predicts that method-only interventions will fail where the error is institutionally load-bearing, and that successful interventions will require changes to the structures that make the error productive.
The simpler explanation: Epistemic errors persist through simple inertia, habit, and the cost of retraining. This is sufficient in some cases. It is insufficient where the error has been explicitly identified, alternative methods are available, and the error persists anyway — because the simpler explanation cannot account for active resistance to correction. Active resistance implies the error is serving a function, which is what constitutive persistence predicts.
Evidence Framework
Documented in Observable Patterns (Tier 1)
The parables listed in each family are real, sourced, and verifiable. Lazebnik (2002, Cancer Cell), Feynman (1974 Caltech commencement), Wald (via Mangel & Samaniego, 2011, Statistical Science, for historical reconstruction), the ISIS-2 trial (1988, The Lancet), Graham (2008). The organizational structure — grouping by error mechanism rather than discipline — is original to this analysis.
The cross-disciplinary citation asymmetry between parables and formal frameworks is observable but has not been measured systematically. Wald’s bullet holes appears in statistics, business, medicine, software engineering, and military strategy textbooks. Heckman correction (the formal treatment of the same selection-bias problem) appears primarily in econometrics and biostatistics. This asymmetry is informal observation, not quantitative citation analysis.
Reasonable Inferences (Tier 2)
The family structure. The claim that these parables cluster into families defined by distinct error operators (rather than being an unstructured list of “biases”) is a pattern inference. The evidence: each family has a clearly distinguishable mechanism, members within families share that mechanism, and parables that span families (Wald spans 1a and 6; Russell’s Chicken spans 4 and 6) do so for identifiable structural reasons. The inference is strengthened by the fact that six independent models, given the taxonomy, converged on the same boundary refinements (sharpen 1/6, split Family 3, move Pauli to Family 2) without coordination.
The two-substrate distinction. The claim that empirical families (1a-7) and social families (8-9) operate on genuinely different substrates is a structural inference. The evidence: empirical families all assume participants are attempting to model reality accurately; social families describe situations where at least one participant has a different objective function entirely. The distinction predicts different intervention responses: empirical errors should yield to better tools and reasoning; social errors should resist methodological reform because the “error” serves the actor’s purposes.
The 5/8 phase transition. Many systems drift from sincere mimicry (Family 5) to strategic exploitation (Family 8) as actors discover the arbitrage potential in institutional forms. This is observable in compliance processes, academic publishing, and corporate metrics. The transition typically follows a pattern: ritual established with genuine intent → actors notice that performing the ritual satisfies requirements regardless of substance → subset of actors begins optimizing the performance rather than the function → system reaches equilibrium where form and function have decoupled.
Boundary porosity. Goodhart’s Law spans both substrates. Wald spans Families 1a and 6. Russell’s Chicken spans Families 4 and 6. These overlaps are features, not bugs — they indicate that some parables compress multiple mechanisms, and the family assignment depends on which mechanism is operative in a given application.
Structural Hypotheses Requiring Additional Evidence (Tier 3)
Constitutive persistence. The hypothesis that epistemic errors persist because the error-generating capability is structurally coupled to the system’s productive capacity. (Developed above as a standalone section because it has cross-family implications.) Falsification condition: if well-documented epistemic errors routinely dissolve once formally identified and alternative methods are available, constitutive persistence is unnecessary. If errors persist despite awareness and available alternatives, and resist intervention attempts that preserve the error-generating capability, constitutive persistence is supported.
Narrative transmission. The hypothesis that parables propagate across disciplines because they compress mechanisms into portable cognitive units. This has at least three competing versions:
The cognitive constraint version claims human cognition processes concrete narratives more efficiently than abstract principles — a permanent architectural feature.
The cognitive simulability version (stronger and more specific) claims the operative constraint is not compression per se but mental runnability: parables succeed because they are agent-centered (humans, animals, actors), causally explicit (the mechanism is visible), and single-step inferential (one mental move from setup to insight). Compare: Wald → “missing holes” → one inversion. Heckman → multi-step statistical correction. The constraint may be simulability rather than length. This version predicts that a non-narrative but highly simulable visualization should spread like a parable, while a short but causally opaque narrative should fail.
The institutional barrier version claims academic culture rewards technical depth over translation, and parables escape these barriers through brevity. Game theory, Bayesian reasoning, and network theory all achieved significant cross-disciplinary penetration as formal frameworks — but only after prestigious textbooks, courses, funding, and implementable algorithms lowered the activation energy.
The social risk version claims sharing a parable is low-status-risk (“it’s just a story”) while sharing a formal statistical correction is high-status-risk (it claims expertise and invites falsification).
These versions are not mutually exclusive. The transmission asymmetry likely involves all four operating simultaneously. Falsification condition for the cognitive versions: if gap families (those lacking flagship parables) show comparable cross-disciplinary recognition to established families, cognitive constraints are not the primary transmission mechanism. Testable through recognition surveys across fields.
Social substrate under-mapping. The taxonomy proposes only two families on the social substrate versus seven on the empirical substrate. This asymmetry could reflect incomplete mapping (more social families exist), genuine distribution (epistemic failures cluster on the empirical substrate), or observer bias (social-substrate errors are harder to recognize and categorize, which would itself be a Family 1a problem applied to the taxonomy).
Alternative Explanations Considered
The simpler explanation: this is just a list of cognitive biases with a fancier organizing principle.
The existing biases-and-heuristics literature (Kahneman & Tversky, Gigerenzer’s competing program, the rationalist community’s collections) already catalogs most of these errors. The taxonomy could be dismissed as rearranging familiar deck chairs.
Why insufficient: Flat lists of biases mix mechanisms, symptoms, and metaphors. “Survivorship bias” (a selection effect) and “Texas Sharpshooter fallacy” (a post-hoc pattern imposition) appear on the same bias lists despite having completely different error operators requiring different corrections. Survivorship bias (Family 6) requires debiasing the sample — modeling the censoring process or collecting the missing data. Texas Sharpshooter (Family 4) requires pre-registration or prediction markets — temporal discipline that separates discovery from confirmation. Someone trained on a flat list treats both as “statistical bias — be careful with data.” Someone trained on the family taxonomy makes different diagnostic moves.
What would settle it: If someone trained on the family taxonomy makes different intervention choices than someone trained on a flat bias list — and those choices produce measurably better outcomes — the mechanism-level organization adds real value. If both produce equivalent outcomes, the taxonomy is decorative.
A competing structural explanation: the taxonomy is an artifact of the organizing framework, not a discovery about the parables themselves.
Any sufficiently flexible classification system can sort items into apparently coherent groups. The “families” might reflect the classifier’s theoretical commitments rather than genuine structure in the parables. A different classifier with different commitments might produce a different but equally coherent taxonomy.
What would distinguish the cases: If independent classifiers, given the same parables without the family structure, converge on similar groupings (high inter-rater reliability), the structure is likely in the parables. If they produce divergent groupings, the structure is likely in the classifier. The six-model review provides preliminary evidence — all six converged on the same boundary refinements — but this was conducted with the proposed structure in view, not independently. A clean test would require cross-framework convergence without prior alignment.
Current State
Established Families
| # | Family | Error Operator | Flagship |
|---|---|---|---|
| 1a | Perceptual Filter | Instrument limits detection | Eddington’s Fish Net |
| 1b | Cognitive Boundary | Framework limits conception | Fish and Turtle |
| 2 | Inventory ≠ Explanation | Catalog confused with theory | Lazebnik’s Radio |
| 3a | Metric Capture | Proxy becomes goal | Goodhart’s Law |
| 3b | Adaptive Response | System reorganizes around intervention | Cobra Effect |
| 4 | Pattern ≠ Signal | Discovered patterns treated as predicted | ISIS-2 Astrological Signs |
| 5 | Form Mimics Function | Ritual mistaken for mechanism | Feynman’s Cargo Cults |
| 6 | Selection Distorts Sample | Filtered sample treated as population | Wald’s Bullet Holes |
| 7 | Dismantling Without Causal Model | Structure removed without understanding function | Chesterton’s Fence |
| 8 | Arbitrage of Intent | Formal/substantive gap exploited | The Vegetarian Cat |
| 9 | Game Misidentification | Epistemic contest assumed in positional game | The Donkey and the Tiger |
Promoted from Incubating
| Family | Error Operator | Flagship |
|---|---|---|
| Composition Fallacy | Local properties don’t survive aggregation | Braess’s Paradox (1968): adding a fast new road causes everyone to reroute; total travel time increases. The shortcut that made the commute worse for everyone. |
| Legibility Trap | Formalization destroys informal function | The Prussian Forest (via James Scott): foresters replaced messy, diverse woods with “legible” rows of a single species to maximize timber yield. The simplified forest initially produced more lumber. Within a generation the ecosystem collapsed — soil depleted, pest resistance gone, yields cratering — because the “mess” was functional. |
Still Incubating
| Family | Mechanism | Parable Status |
|---|---|---|
| Performativity | Models reshape the systems they describe | Bank Run nominated; needs sharper distinction from Family 3b. Performativity changes the truth conditions of the model, not just the system state. |
| Expertise Collapse | Domain competence generates cross-domain overconfidence | “Nobel Disease” nominated — laureate concludes prize-winning expertise transfers to nutrition or oncology. Needs a tighter single-move parable. |
Unresolved Questions
Interaction dynamics. The taxonomy currently classifies error types but does not yet describe how they interact. Observable cascades include: Family 6 (selection distortion) enabling Family 4 (pattern hallucination) — the filtered sample generates apparent structure that post-hoc analysis then “discovers.” Family 1a (filter) hardening into Family 5 (cargo cult) — when the instrument’s limitations become ritualized. Family 9 (game misidentification) concealing Family 3b (adaptive response) — the positional player’s strategic adaptations are invisible to the empirical player, who interprets them as noise. Mapping these interaction dynamics is what would move the taxonomy from a parts list (Family 2 level) to a circuit diagram.
Family completeness. Do the social families (8, 9) exhaust the space of social-substrate errors? The Overton window — constraints on what can be expressed determining what can be investigated — may constitute a distinct social family rather than a contextual feature of all families.
Incubation criteria. What promotes an incubating family to established? Proposed threshold: a shared mechanism clearly distinguished from existing families, at least three members from different disciplines, and a flagship parable with sufficient narrative compression for cross-disciplinary transmission.
The self-application test. The taxonomy claims to organize epistemic failures by mechanism. The taxonomy itself could be a Family 5 entity — having the form of a structural classification without the function of genuine predictive or diagnostic power. It could also be a Family 2 entity — a parts list that users memorize without understanding the mechanisms. The distinction requires testing: does the taxonomy produce different practical recommendations than a flat bias list? Does it predict intervention outcomes? If not, it is decorative rather than functional.
